« Previous 1 2 3 4 Next »
Central logging for Kubernetes users
Shape Shifter
Loki in Practice
Loki can be virtualized easily and that was even one of the core requirements of the developers. Because Loki requires fewer resources than ELK, it does not need massive hardware resources. Like Prometheus, Loki is a Go application, which you can get from GitHub [1]. However, it is not necessary to roll out and launch Loki as a Go binary. In the best cloud style, the Loki developers offer Docker images of the solution on Docker Hub, so you can deploy them locally straightaway. Therefore, the only external task is to send the configuration file to the container.
Under the Hood
What looks so easy at first glance requires a combination of several components on the inside. In the style of a cloud-native application, Loki comprises several components that need to interact to succeed. However, the architecture on which Loki is based is not that specific to Loki. It simply recycles large parts of the development work already done for Cortex (Figure 1). Because Cortex works well, there's no reason why Loki shouldn't.
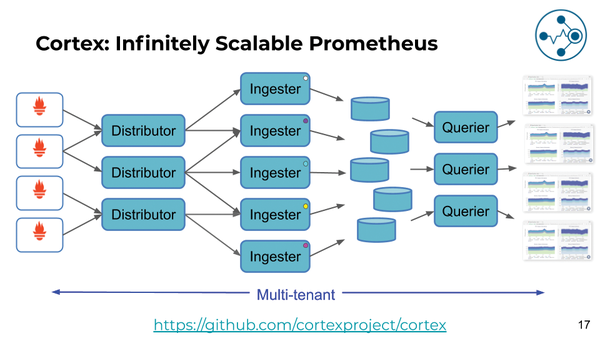 Figure 1: Loki inherits much of its design from Cortex, which sees itself as a more scalable Prometheus. © Grafana
Figure 1: Loki inherits much of its design from Cortex, which sees itself as a more scalable Prometheus. © Grafana
Log data that reaches Loki is grabbed by the Distributor component; several instances of this service are usually running. With large-scale systems, the number of incoming log messages can quickly reach many millions depending on the type of services running in the cloud, so a single Distributor instance would hardly be sufficient. However, it would also be problematic to drop these incoming log messages into a database without filtering and processing. If the database survived the onslaught, it would inevitably become a bottleneck in the logging setup.
The active instances of the Distributor therefore categorize the incoming data into streams on the basis of labels and forward them to Ingesters, which are responsible for processing the data. In concrete terms, processing means forming log packages (chunks) from the incoming log messages, which can be compressed by Gzip. Like the Distributors, the several Ingester instances also run at the same time, forming a ring architecture over which a Distributor applies a consistent hash algorithm to calculate which of the Ingester instances is currently responsible for a particular label.
Once an Ingester has completed a chunk of a log, the final step en route to central logging then follows: storing the information in the storage system to which Loki is connected. As already mentioned, Loki differs considerably from its predecessor Prometheus, for which a time series database is a key aspect.
Loki, on the other hand, does not handle metrics, but text, so it stores the chunks and information about where they reside separately. The index lists all known chunks of log data, but the data packets themselves are located on the same storage facility configured for Loki.
What is interesting about the Loki architecture is that it almost completely separates the read and write paths. If you want to read logs from Loki via Grafana, a third service is used in Loki, the Querier, which accesses the index and stored chunks in the background. It also communicates briefly with the Ingesters to find log entries that have not yet been moved to storage. Otherwise, read and write operations function completely independently.
Scaling Works
Looking at the overall Loki construct, it becomes clear that the design of the solution fits perfectly with the requirements faced by the developers: scalable, cost-effective with regard to the required hardware, and as flexible as possible.
The index ends up with Cassandra, Bigtable, or DynamoDB, all of which are known to scale horizontally without restrictions. The chunks are stored in an object store such as Amazon S3, which also scales well. The components belonging to Loki itself, such as the Distributors and Queriers, are stateless and therefore scale to match requirements.
Only the Ingester is a bit tricky. Unlike its colleagues, it is a stateful application that simply must not fail. However, the implemented ring mechanism provides the features required for sharding, so you can deploy any number of Ingesters to suit needs. Loki scales horizontally without limits. Because it does not store the contents of the incoming log data, it has a noticeably smaller hardware footprint than a comparable ELK stack.
The Loki documentation contains detailed tips on scalability, but briefly, to scale horizontally, Loki needs the Consul cluster consensus mechanism to coordinate the work steps beyond the borders of nodes. If you want to use Loki in this way, it is a very good idea to read and understand the corresponding documentation, because a scaled Loki setup of this kind is far more complex than a single instance.
Loki is noticeably easier to implement than Prometheus, because Loki does not save the payload (i.e., the log data) itself at the end. This task is handled by external storage, which provides the high availability on which Loki relies.
« Previous 1 2 3 4 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Getting started with Prometheus
 Prometheus is a centralized time series database with metrics, scraping, and alerting logic built in. We help you get started monitoring with Prometheus.
Prometheus is a centralized time series database with metrics, scraping, and alerting logic built in. We help you get started monitoring with Prometheus. -
Monitoring container clusters with Prometheus
 In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation.
In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation. -
Grafana and Prometheus customized dashboards
 Grafana analytics and visualization dashboards plus the Prometheus monitoring and alerting tool make possible extensive custom reporting and alerting systems.
Grafana analytics and visualization dashboards plus the Prometheus monitoring and alerting tool make possible extensive custom reporting and alerting systems. -
Time-series-based monitoring with Prometheus
 As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications.
As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications. -
Make better use of Prometheus with Grafana, Telegraf, and Alerta
 The Prometheus monitoring tool might not always look like one of the Titans, but add-ons like Alerta or Telegraf can improve its looks.
The Prometheus monitoring tool might not always look like one of the Titans, but add-ons like Alerta or Telegraf can improve its looks.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
