
Lead Image © SV-Luma, 123RF.com
Optimizing utilization with the EDF scheduler
Mr. Efficient
Linux kernel 3.14 added an optional scheduling method known as Earliest Deadline First (EDF). EDF scheduling uses a scheme where the process closest to its deadline is the next process scheduled for execution.
EDF is mainly used in systems that need to meet time requirements, and it has been known to handle tasks on time even in cases for which common priority-driven scheduling fails (see Figure 1 and the "Utilization" box).
Utilization
The utilization of a single-core system may usually only be at a maximum of 69 percent for priority-driven scheduling and still process tasks on time. The Earliest Deadline First scheduler, on the other hand, allows almost 100 percent utilization of the system.
Utilization is a measure of whether the tasks of a real-time system comply with time limits in all circumstances. Utilization is similar to load, but it is calculated according to a slightly different formula,
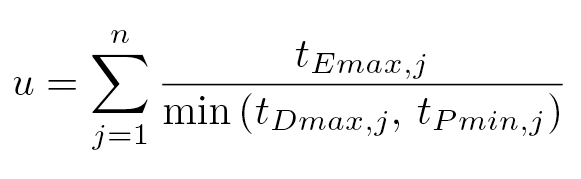
where the numerator is the maximum processing time (Worst Case Execution Time, WCET) of task j , t _{Dmax ,j } is its maximum completion time (maximum deadline), and t _{Pmin ,j } is its minimum time interval before waking the same task (period).
If, with priority-controlled scheduling, utilization is smaller or equal as a function of the number of
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Visualizing kernel scheduling
 The Google SchedViz tool lets you visualize how the Linux kernel scheduler allocates jobs among cores and whether they are being usurped.
The Google SchedViz tool lets you visualize how the Linux kernel scheduler allocates jobs among cores and whether they are being usurped. -
Law of Averages – Load Averaging
Load averaging can be a source of confusion for admins. We provide a look at some basic considerations.
-
Linux I/O Schedulers
 The Linux kernel has several I/O schedulers that can greatly influence performance. We take a quick look at I/O scheduler concepts and the options that exist within Linux.
The Linux kernel has several I/O schedulers that can greatly influence performance. We take a quick look at I/O scheduler concepts and the options that exist within Linux. -
Resource Management with Slurm

One way to share HPC systems among several users is to use a software tool called a resource manager. Slurm, probably the most common job scheduler in use today, is open source, scalable, and easy to install and customize.
-
Linux I/O Schedulers

The Linux kernel has several I/O schedulers that can greatly influence performance. We take a quick look at I/O scheduler concepts and the options that exist within Linux.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
