« Previous 1 2 3 4 Next »
OpenStack workshop, part 3:Gimmicks, extensions, and high availability
Wide Load
High Availability
The good news is that Folsom is nothing like as clueless in terms of high availability (HA) as earlier OpenStack versions were. Efforts made by yours truly and others to push toward integrating OpenStack services with Pacemaker clusters now mean that the major part of the OpenStack installation can be designed for HA. Incidentally, this is another reason to rely on object storage solutions like Ceph: They come with HA built in, meaning that admins do not need to worry about redundancy.
The remaining problem concerns the reliability of the OpenStack infrastructure and of the VMs themselves. For the infrastructure component, Pacemaker is an obvious choice (Figure 4): It provides a comprehensive toolbox that lets admins configure services redundantly on multiple machines. Almost all OpenStack services can thus be upgraded to high availability, including Keystone, Glance, Nova, Quantum, and Cinder [4]. Anyone planning an OpenStack HA setup, however, should not forget two other components: the database, typically MySQL, and the message queue (i.e., RabbitMQ or Qpid).
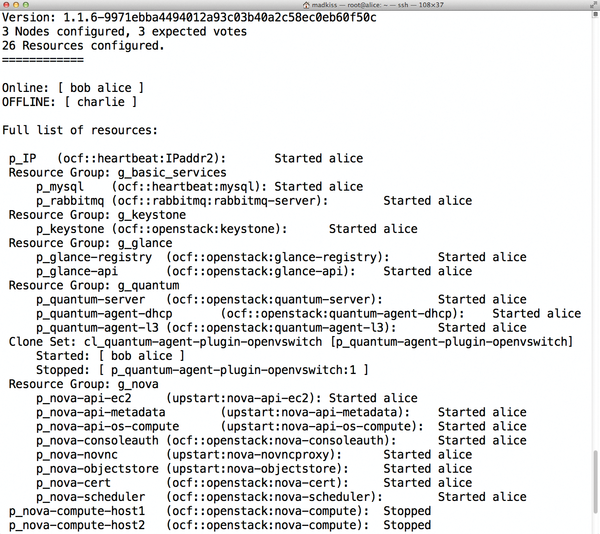 Figure 4: Using Pacemaker to harden an OpenStack setup against failures: a three-node cluster with one node down.
Figure 4: Using Pacemaker to harden an OpenStack setup against failures: a three-node cluster with one node down.
HA for MySQL and RabbitMQ
Several HA options are available for MySQL. The classical method is for MySQL to store its data on shared storage, such as DRBD, with mysqld migrating between two computers. Depending on the size of the database journal, a failover in this kind of scenario can take some time; moreover, the solution does not scale horizontally. Natively integrated solutions such as MySQL Galera are more meaningful; they ensure that the database itself takes care of replication. A detailed article about Galera was published in a previous ADMIN
issue [5].
The situation is similar with the RabbitMQ messaging queue: Again, you could easily implement a failover solution relying on shared storage, which in this case would be preferable to the HA solution that RabbitMQ offers out of the box. In the past, "mirrored queues" have repeatedly been found to be prone to error. If you are considering making RabbitMQ highly available in a Pacemaker setup, you would do better to choose a solution in which the rabbitmq-server migrates between the hosts and /var/lib/rabbitmq is located on shared storage. If you work with more than two nodes and Ceph, you can use CephFS to mount the RabbitMQ data on /var/lib/rabbitmq and resolve the problem of non-scaling storage at a glance.
The remaining overhead in an HA setup consists almost exclusively of integrating the existing OpenStack components with a classic Pacemaker setup. It is beyond the scope at this point to explain a bare metal Pacemaker configuration.
Worth particular notice is that resource agents in line with the OCF standard are now available for almost all OpenStack components. You can unzip them on a system into the /usr/lib/ocf/resource./openstack folder like this:
cd /usr/lib/ocf/resource.d mkdir openstack cd openstack wget -O- https://github.com/madkiss/openstack-resource-agents/archive/master.tar.gz | tar -xzv --strip-components=2 openstack-resource-agents-master/ocf chmod -R a+rx *
To reveal the help text for the nova-compute resource agent, then, you would type:
crm ra info ocf:openstack:nova-compute
The rest is plain sailing.
For each OpenStack service, you need to integrate a resource with the Pacemaker configuration so that services that belong together are grouped (Listing 2, lines 28-33). To make sure all the important services run on the same host, colocation and order constraints set the ratio of resources to one other (lines 38-51). It is worth mentioning that the resource for the Quantum openvswitch plugin agent is a clone resource (line 34): Every service should run on all OpenStack nodes, on which virtual machines should basically also be bootable.
Listing 2
Pacemaker Configuration for OpenStack
01 node alice 02 node bob 03 node charlie 04 primitive p_IP ocf:heartbeat:IPaddr2 params cidr_netmask="24" ip="192.168.122.130" iflabel="vip" op monitor interval="120s" timeout="60s" 05 primitive p_cinder-api upstart:cinder-api op monitor interval="30s" timeout="30s" 06 primitive p_cinder-schedule upstart:cinder-scheduler op monitor interval="30s" timeout="30s" 07 primitive p_cinder-volume upstart:cinder-volume op monitor interval="30s" timeout="30s" 08 primitive p_glance-api ocf:openstack:glance-api params config="/etc/glance/glance-api.conf" os_password="hastexo" os_username="admin" os_tenant_name="admin" os_auth_url="http://192.168.122.130:5000/v2.0/" op monitor interval="30s" timeout="30s" 09 primitive p_glance-registry ocf:openstack:glance-registry params config="/etc/glance/glance-registry.conf" os_password="hastexo" os_username="admin" os_tenant_name="admin" keystone_get_token_url="http://192.168.122.130:5000/v2.0/tokens" op monitor interval="30s" timeout="20s" 10 primitive p_keystone ocf:openstack:keystone params config="/etc/keystone/keystone.conf" os_password="hastexo" os_username="admin" os_tenant_name="admin" os_auth_url="http://192.168.122.130:5000/v2.0/" op monitor interval="30s" timeout="30s" 11 primitive p_mysql ocf:heartbeat:mysql params binary="/usr/sbin/mysqld" additional_parameters="--bind-address=0.0.0.0" datadir="/var/lib/mysql" config="/etc/mysql/my.cnf" log="/var/log/mysql/mysqld.log" pid="/var/run/mysqld/mysqld.pid" socket="/var/run/mysqld/mysqld.sock" op monitor interval="120s" timeout="60s" op stop interval="0" timeout="240s" op start interval="0" timeout="240s" 12 primitive p_nova-api-ec2 upstart:nova-api-ec2 op monitor interval="30s" timeout="30s" 13 primitive p_nova-api-metadata upstart:nova-api-metadata op monitor interval="30s" timeout="30s" 14 primitive p_nova-api-os-compute upstart:nova-api-os-compute op monitor interval="30s" timeout="30s" 15 primitive p_nova-cert ocf:openstack:nova-cert op monitor interval="30s" timeout="30s" 16 primitive p_nova-compute-host1 ocf:openstack:nova-compute params additional_config="/etc/nova/nova-compute-host1.conf" op monitor interval="30s" timeout="30s" 17 primitive p_nova-compute-host2 ocf:openstack:nova-compute params additional_config="/etc/nova/nova-compute-host2.conf" op monitor interval="30s" timeout="30s" 18 primitive p_nova-compute-host3 ocf:openstack:nova-compute params additional_config="/etc/nova/nova-compute-host3.conf" op monitor interval="30s" timeout="30s" 19 primitive p_nova-consoleauth ocf:openstack:nova-consoleauth op monitor interval="30s" timeout="30s" 20 primitive p_nova-novnc upstart:nova-novncproxy op monitor interval="30s" timeout="30s" 21 primitive p_nova-objectstore upstart:nova-objectstore op monitor interval="30s" timeout="30s" 22 primitive p_nova-scheduler ocf:openstack:nova-scheduler op monitor interval="30s" timeout="30s" 23 primitive p_quantum-agent-dhcp ocf:openstack:quantum-agent-dhcp op monitor interval="30s" timeout="30s" 24 primitive p_quantum-agent-l3 ocf:openstack:quantum-agent-l3 op monitor interval="30s" timeout="30s" 25 primitive p_quantum-agent-plugin-openvswitch upstart:quantum-plugin-openvswitch-agent op monitor interval="30s" timeout="30s" 26 primitive p_quantum-server ocf:openstack:quantum-server params os_password="hastexo" os_username="admin" os_tenant_name="admin" keystone_get_token_url="http://192.168.122.130:5000/v2.0/tokens" op monitor interval="30s" timeout="30s" 27 primitive p_rabbitmq ocf:rabbitmq:rabbitmq-server params mnesia_base="/var/lib/rabbitmq" op monitor interval="20s" timeout="10s" 28 group g_basic_services p_mysql p_rabbitmq 29 group g_cinder p_cinder-volume p_cinder-schedule p_cinder-api 30 group g_glance p_glance-registry p_glance-api 31 group g_keystone p_keystone 32 group g_nova p_nova-api-ec2 p_nova-api-metadata p_nova-api-os-compute p_nova-consoleauth p_nova-novnc p_nova-objectstore p_nova-cert p_nova-scheduler 33 group g_quantum p_quantum-server p_quantum-agent-dhcp p_quantum-agent-l3 34 clone cl_quantum-agent-plugin-openvswitch p_quantum-agent-plugin-openvswitch 35 location lo_host1_prefer_alice p_nova-compute-host1 10000: alice 36 location lo_host2_prefer_bob p_nova-compute-host2 10000: bob 37 location lo_host3_prefer_charlie p_nova-compute-host3 10000: charlie 38 colocation co_g_basic_services_always_with_p_IP inf: g_basic_services p_IP 39 colocation co_g_cinder_always_with_g_keystone inf: g_cinder g_keystone 40 colocation co_g_glance_always_with_g_keystone inf: g_glance g_keystone 41 colocation co_g_keystone_always_with_p_IP inf: g_keystone p_IP 42 colocation co_g_nova_always_with_g_keystone inf: g_nova g_keystone 43 colocation co_g_quantum_always_with_g_keystone inf: g_quantum g_keystone 44 order o_cl_quantum-agent-plugin-openvswitch_after_g_keystone inf: g_keystone:start cl_quantum-agent-plugin-openvswitch:start 45 order o_g_basic_services_always_after_p_IP inf: p_IP:start g_basic_services:start 46 order o_g_cinder_always_after_g_keystone inf: g_keystone:start g_cinder:start 47 order o_g_glance_always_after_g_quantum inf: g_quantum:start g_glance:start 48 order o_g_keystone_always_after_g_basic_services inf: g_basic_services:start g_keystone:start 49 order o_g_keystone_always_after_p_IP inf: p_IP:start g_keystone:start 50 order o_g_nova_always_after_g_glance inf: g_glance:start g_nova:start 51 order o_g_quantum_always_after_g_keystone inf: g_keystone:start g_quantum:start
VM Failover with OpenStack
The three p_nova-compute instances (Listing 2, lines 16-18) need a special mention; they allow you to restart virtual machines on other hosts if the original host on which the VMs were running is no longer available. Previously this was a sensitive issue in OpenStack because the environment itself – at least in Folsom – did not initially notice the failure of a node. But the back door used in the example in this article lets you retrofit a similar function. Each instance of nova-compute allows you to specify additional configuration files. Their values overwrite existing values, and the last one wins. A host= entry tells a compute instance what its name is; if this value is not set, Nova usually assumes the hostname of the system. The trick is to remove the mapping between the hostname and the VMs running on it. Whether the Nova compute instance named host1 runs on node 1, node 2, or node 3 is initially irrelevant, and VMs that are running on host1 can be started on any server, as long as it has a Nova compute instance that thinks it is host1.
The nova.conf used in the previous article [1] also includes the resume_guests_state_on_host_boot = true option; this means that VMs on a host are set to the state in which Nova last saw them after launching nova-compute. In plain talk: If server 1 is running a nova-compute with host=host1 set, Nova will remember which VMs run on this host1. If server 1 crashes, in this example, Pacemaker restarts the nova-compute host1 instance on another server, and Nova then boots the VMs that previously lived on server 1 on the other server.
For this approach to work, all nova-compute instances need access to the same Nova instances directory. The example here solves the problem by mounting /var/lib/nova/instances on a CephFS on all servers, thus providing the same files to all hosts (Figure 5).
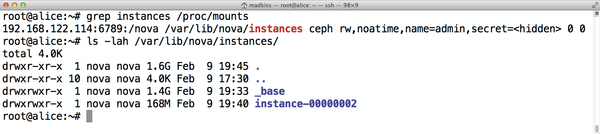 Figure 5: The /var/lib/nova/instances directory is a CephFS mount on all hosts; all the servers thus see the same VM data.
Figure 5: The /var/lib/nova/instances directory is a CephFS mount on all hosts; all the servers thus see the same VM data.
A universal caveat applies to OpenStack Pacemaker setups like any other Pacemaker installation: Keep the versions of the programs identical between the computers. Any config files required by services must also be in sync between the hosts. If these conditions are met, a high-availability OpenStack setup is no problem at all.
« Previous 1 2 3 4 Next »
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
OpenStack: What's new in Grizzly?
 In mid-April, the OpenStack developers published the latest version of their free cloud environment, code-named Grizzly.
In mid-April, the OpenStack developers published the latest version of their free cloud environment, code-named Grizzly. -
OpenStack workshop, part 2: OpenStack cloud installation
 The first article in this workshop looked at the theory behind OpenStack; the second part takes a more hands-on approach: How can you set up an OpenStack cloud on a greenfield site?
The first article in this workshop looked at the theory behind OpenStack; the second part takes a more hands-on approach: How can you set up an OpenStack cloud on a greenfield site? -
OpenStack: Shooting star in the cloud
 OpenStack is attracting lots of publicity. Is the solution actually qualified as a cloud prime mover? We take a close look at the OpenStack cloud environment and how it works.
OpenStack is attracting lots of publicity. Is the solution actually qualified as a cloud prime mover? We take a close look at the OpenStack cloud environment and how it works. -
OpenStack: Shooting star in the cloud

OpenStack is attracting lots of publicity. Is the solution actually qualified as a cloud prime mover? We take a close look at the OpenStack cloud environment and how it works.
-
Ceph and OpenStack Join Forces

When building cloud environments, you need more than just a scalable infrastructure; you also need a high-performance storage component. We look at Ceph, a distributed object store and filesystem that pairs well in the cloud with OpenStack.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
