Workflow-based data analysis with KNIME
Analyze This!
REST
REST (representational state transfer) is based, among other things, on the principle of statelessness and addressability of resources on the web. Normally, REST interfaces use the JSON or XML format. Corresponding data types and processing nodes exist in KNIME for both formats (e.g., the JSON Path and XPath nodes).
To begin, you have to acquire the data. KNIME offers a GET Request node in the Tools & Services | REST Web Services category. This category also includes nodes for sending data to a REST service and for deleting and modifying resources. The user simply passes the URL of the interface to the GET Request node and then downloads the data during execution and displays it in a table.
In the sample workflow, the GET Request node is replaced by a JSON Reader node, because the interface for the subscription data does not exist. The output from JSON Reader is shown in Figure 12.
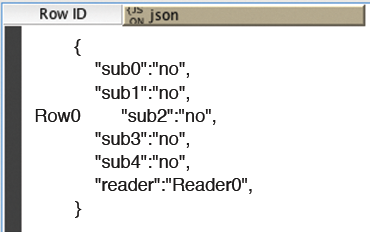 Figure 12: The subscription table in JSON format.
Figure 12: The subscription table in JSON format.
Because most KNIME nodes need data in tabular format and cannot inspect a JSON object, you need to transform the received data so that each reader ID corresponds to a row and each subscription to a column. To do so, combine the JSON to Table node and the RowID node to create the table as shown in Figure 13. With the Joiner node, the subscription data can now be linked with the reader preferences (determined in the previous example), as can be seen from the workflow in Figure 14.
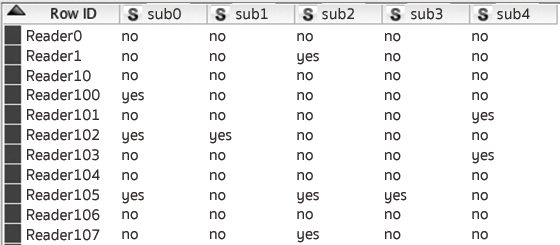 Figure 13: The JSON-generated table with information about which readers subscribed to which newsletters.
Figure 13: The JSON-generated table with information about which readers subscribed to which newsletters.
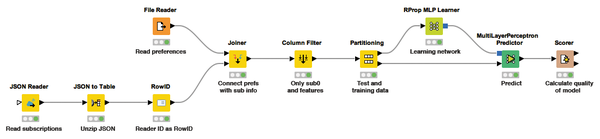 Figure 14: The entire workflow for testing a model, including importing the data. The data is divided and a neural network learns how to the predict the interest in subscription 0. KNIME uses a Scorer node to compute the quality of the model.
Figure 14: The entire workflow for testing a model, including importing the data. The data is divided and a neural network learns how to the predict the interest in subscription 0. KNIME uses a Scorer node to compute the quality of the model.
Machine Learning
Now that all the required data is summarized in a table, you can create prediction models that will make it possible to predict later whether a reader without a subscription might be interested in signing up for a newsletter on a specific topic. Strictly speaking, each topic requires its own model, but we are just using a single model here to present KNIME's machine learning capabilities.
In machine learning, a general distinction is made between supervised and unsupervised learning. The clustering in the first article on KNIME was an example of unsupervised learning, because the processed datapoints had no known classification or label.
In supervised learning, on the other hand, data has labels that assign a value to a datapoint, which then needs to be predicted later for new data. Predicting a numerical value is referred to as a regression, and predicting a category is a classification.
Predicting whether a reader would be interested in a newsletter is a classification, because the value to be predicted is either yes or no (i.e., a binary classification). A little more background information on this topic can be found in the box "Classification in a Nutshell."
Classification in a Nutshell
Classification is the automatic differentiation of objects (things or persons) into different classes (e.g., Linux and Windows users). For a computer to handle such a classification, the objects must be described by a fixed number of numerical characteristics (e.g., the age of the person), nominal characteristics (e.g., the gender of the person), or a combination thereof. On the basis of these characteristics, a computer function can finally assign a class to the corresponding objects.
As a rule, this function (the classification algorithm) now uses a model containing the knowledge about the classification. This model, in turn, is a priori unknown and is usually first determined from training data.
The results, of course, are rarely perfect, either because of the training data or the choice of algorithm. The quality is therefore often determined with test data, which comprises objects whose classes are known so that the model's prediction can be checked.
To determine whether the model to be learned works well, you first need to split the data into a test dataset to estimate its generalization capability (i.e., to see how good the predictions are for previously unseen data) and a training dataset to learn the model.
An evaluation with the same data as used during training generally leads to overly optimistic results. The Partitioning node divides the data into two tables. An 80/20 split is usually a good guideline, with 80 percent for learning and 20 percent for evaluation.
Machine learning is a large field of research and, accordingly, has many different approaches to statistical modeling. One very popular approach is the neural network. In KNIME, a neural network is taught by the RProp MLP Learner node (RProp stands for the algorithm used here, and MLP for Multilayer Perceptron, a network with many layers).
When configuring the learner algorithm, the KNIME user only selects the column that contains the value to be predicted. Therefore, if the learner is connected to the 80 percent output from the Partitioning node and executed, the node trains a neural net that has learned to determine which subscriptions the readers are interested in on the basis of their preferences. Armed with the MultiLayerPerceptron Predictor and Scorer nodes, you can use the previously ignored 20 percent of the data now to check how good the model really is (right two nodes in Figure 14). Other suitable learners include Random Forest , Gradient Boosted Trees , and Support Vector Machines .
Loops
Each of the five newsletters has its own model to learn. Although the simple solution would be to create five workflows, it is not really a practical solution, because if the learning process changes later, several workflows (or workflow parts) would have to be adapted. An easier method is to use loops that execute part of the workflow more than once with different parameters.
In KNIME, you can encapsulate multiple-execution sections in various paired Loop Start and Loop End nodes. Depending on the type of the start node, the workflow between the loop nodes is executed once per line, or for specific columns, or until a specific condition occurs. The end node needs to collect the data from the loop passes and aggregate them, if necessary.
The table the models use for learning (Figure 15) has an extra column for each newsletter (subscription) type (0 to 4). The goal is thus to learn one model per column that predicts the column's value. KNIME offers the Column List Loop Start node for iterating over columns. In its configuration dialog, you can select the columns over which the workflow part of the loop will execute.
 Figure 15: The training data table. The last five columns are predicted with the help of the first five columns and separate models in each case.
Figure 15: The training data table. The last five columns are predicted with the help of the first five columns and separate models in each case.
The reader preferences in columns 2 through 6 and one of the five sub0 to sub4 columns are available within the loop. Now you can connect RProp MLP Learner to the Column List Loop Start node to learn the corresponding model.
The division into test and training data in the loop is unnecessary, because that division is only there to evaluate whether a model is capable of delivering good results. Once this has been determined, the entire available dataset is ready for learning. The changed workflow that uses the loops is shown in Figure 16.
 Figure 16: The neural network workflow for classifying readers.
Figure 16: The neural network workflow for classifying readers.
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
HPC Data Analytics

As data analytics workloads become more common, HPC administrators need to assess their hardware, software, and processes.
-
Tool your HPC systems for data analytics
 As data analytics workloads become more common, administrators need to assess their hardware, software, and processes.
As data analytics workloads become more common, administrators need to assess their hardware, software, and processes. -
Measuring the performance health of system nodes
 Many HPC systems check the state of a node before running an application, but not very many check that the performance of the node is acceptable before running the job.
Many HPC systems check the state of a node before running an application, but not very many check that the performance of the node is acceptable before running the job. -
Performance Health Check

Many HPC systems check the state of a node b efore running a n application, but not very many check that the performance of the node is acceptable before running the job.
-
Kickstack: OpenStack with Puppet

Kickstack uses Puppet modules to automate the installation of OpenStack and facilitate maintenance.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
