
Understanding the I/O pattern of your application is the starting point for improving its I/O performance, especially if I/O is a fairly large part of your application’s run time.
Parallel I/O
Lately I’ve been looking at application timing to find bottlenecks or time-consuming portions of code. I’ve also been reading articles about improving applications by parallelization. Once again, this has led me to examine application I/O and, in particular, the fact that many applications handle I/O serially – even parallel applications – which can result in an I/O performance bottleneck.
I/O in serial applications is simple: one thread or process does it all. It doesn’t have to read data and then pass it along to another process or thread. It doesn’t collect data from other processes and threads and perform the I/O on their behalf. One thread. One I/O stream.
To improve application performance or to tackle larger problems, people have turned to parallelism. This means taking parts of the algorithm that can be run at the same time and doing so. Some of these code portions might have to handle I/O, which is where things can get complicated.
What it comes down to is coordinating the I/O from various threads/processes (TPs) to the filesystem. Coordination can include writing data to the appropriate location in the file or files from the various TPs so that the data files are useful and not corrupt. POSIX filesystems don’t have mechanisms to help multiple TPs write to the filesystem; therefore, it is up to the application developer to code the logic for I/O with multiple TPs.
I/O from a single TP is straightforward and represents coding in everyday applications.
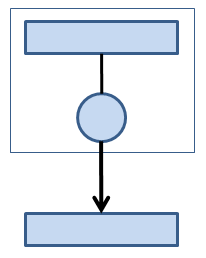 Figure 1: I/O from a single thread/process.
Figure 1: I/O from a single thread/process.
Figure 1 shows one TP handling I/O for a single file. Here, you don’t have to worry about coordinating I/O from multiple TPs because there is only one. However, if you want to run applications faster and for larger problems, which usually involves more than one TP, I/O can easily become a bottleneck. Think of Amdahl’s Law.
Amdahl’s Law says that the performance of a parallel application will be limited by the performance of the serial portions of the applications. Therefore, if your I/O remains a serial function, the performance of the application is driven by the I/O.
To better understand how Amdahl’s Law works, I’ll examine a theoretical application that is 80% parallelizable (20% is serial, primarily because of I/O). For one process, the wall clock time is assumed to be 1,000 seconds, which means that 200 seconds is the serial portion of the application. By varying the number of processes from 1 to 64, you can see in Figure 2 how the wall clock time on the y-axis is affected by the number of processes on the x-axis.
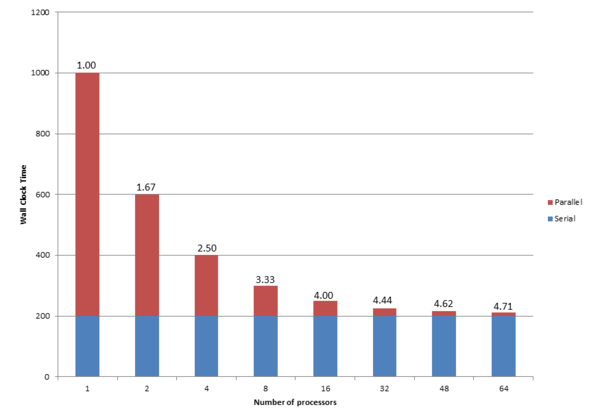 Figure 2: Influence of Amdahl's Law on a 20% serial application by number of processes.
Figure 2: Influence of Amdahl's Law on a 20% serial application by number of processes.
The blue portion of each bar is the serial time, and the red portion represents time required by the parallel portion of the application. Above each bar is the speedup factor. The starting point on the left shows that the sum of the serial portion and the parallel portion is 1,000 seconds, with 20% serial (200 seconds) and 80% parallel (800 seconds), but with only one process. Amdahl’s Law says the speedup is 1.00.
As the number of processes increase, the wall clock time of the parallel portion decreases. The speed-up increases from 1.00 with one process to 4.71 using 64 processes. Of course, the wall clock time for the serial portion of the application does not change; it stays at 200 seconds regardless of the number of processes.
As the number of processes increase, the total run time of the application approaches 200 seconds, which is the theoretical performance limit of the application, primarily because of serial I/O. The only way to improve application performance is to improve I/O performance by handling parallel I/O in the application.
Simple Parallel I/O
The first way to approach parallel I/O, and one that many applications use, is to have each TP write to its own file. The concept is simple, because there is zero coordination between TPs. All I/O is independent of all other I/O. Figure 3 illustrates this common pattern, usually called “file-per-process.”
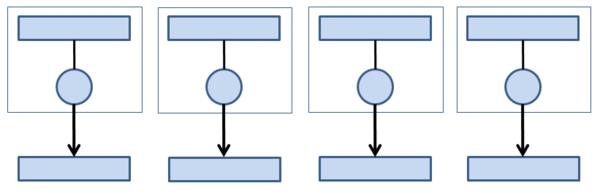 Figure 3: Parallel I/O via separate files (file-per-process).
Figure 3: Parallel I/O via separate files (file-per-process).
Each TP performs all I/O to its own file. You can keep them all in the same directory by using different file names or you can put them in different directories if you prefer.
As you start to think about parallel I/O, you need to consider several aspects. First, the filesystem should have the ability to keep up as parallelism increases. For the file-per-process pattern, if each TP performs I/O at a rate of 500MBps, then with four TPs the total throughput is 2GBps. The storage needs to be able to sustain this level of performance. The same is true of IOPS (input/output operations per second) and metadata performance. Parallelizing an application won’t help if the storage and filesystem cannot keep up.
The second consideration is that the data files will be used outside your application. Does the data need to be post-processed (perhaps visualized) once it’s created? Does the data read by the application need to be prepared by another application? If so, you need to make sure the other application creates the input files in the proper format. Think of the application workflow as a whole.
For the example in Figure 3, if you used four TPs and each handled their own I/O, you have four output files and probably four input files (you can allow each TP to read the same file). Any application that uses the output from the application will need to use all four files. If you stay with the file-per-process approach, you will likely have to stay with four TPs for any applications that use the data, which now introduces an artificial limitation into the workflow (four TPs).
One option is to write a separate application that reads the separate files and combines them into a single file (in the case of output data) or reads the input file and creates separate files for input (in the case of input data). Although this solution eliminates the limitation, it adds another step or two to the workflow.
Performing file-per-process is probably the easiest way to achieve parallel I/O, because it involves less modification to the original serial or parallel application while greatly improving the I/O portion of the run time. However, as the number of TPs increases, you could end up with a large number of input and output files, making data management a pain in the neck.
Moreover, as the number of files increases, the metadata performance of the filesystem comes under increasing pressure. Instead of a few files, the filesystem now has to contend with thousands of files all doing a series of open(), read() or write(), close() [or even lseek()] operations at the same time.
Single Thread/Process I/O
Another option for the parallel I/O problem is to use one TP to handle all I/O. This solution really isn’t parallel I/O, but it is a common solution that avoids the complications of having multiple TPs write to a single file. This option also solves the data management problem because everything is in a single file – both input and output – and eliminates the need for creating auxiliary applications to either split up a file into multiple pieces or combine multiple pieces into a single file. However, it does not improve I/O performance, because I/O does not take place in parallel.
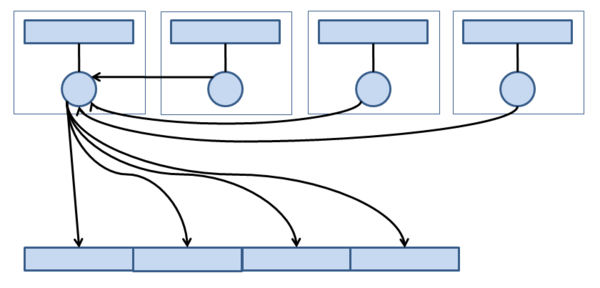 Figure 4: Multiple threads/processes doing I/O via a single thread/process.
Figure 4: Multiple threads/processes doing I/O via a single thread/process.
You can see in Figure 4 that the first TP (the “I/O thread/process”) takes care of I/O to the file(s). If any of the other TPs want to write data, they send it to the I/O TP, which then writes to the file. To read a file, the I/O TP reads the data and then sends it to the appropriate TP.
Using the single I/O TP approach can require some extra coding to read and write the data, but many applications use this approach because it simplifies the I/O pattern in the application: You only have to look at the I/O pattern of one TP.