
Kicking write I/O operations into overdrive with the Linux device mapper writecache.
Linux device mapper writecache
The idea of block I/O caching isn't revolutionary, but it still is an extremely complex topic. Technically speaking, caching as a whole is complicated and a very difficult solution to implement. It all boils down to the I/O profile of the ecosystem or server on which it is being implemented. Before I dive right in, I want to take a step back, so you understand what I/O caching is and what it is intended to address.
What Is I/O Caching?
A computer cache is a component (typically leveraging some sort of performant memory) that temporarily stores data for current write and future read I/O requests. In the event of write operations, the data to be written is staged and will eventually be scheduled and flushed to the slower device intended to store it. As for read operations, the general idea is to read it from the slower device no more than once and maintain that data in memory for as long as it is still needed. Historically, operating systems have been designed to enable local (and volatile) random access memory (RAM) to act as this temporary cache. Although it performs at stellar speeds, it has its drawbacks:
- It is expensive.
- Capacities are small.
- More importantly, it is volatile. If power is removed from RAM, data is lost.
As unrealistic as it might seem, the ultimate goal is never to touch the slower device storing your data with either read or write I/O requests (Figure 1). Fortunately, other forms of performant, cheap, high-density, and persistent memory devices exist that do not perform as fast as RAM but that do still perform extremely well -- enough so that I will demonstrate their use in the following exercise with noticeable results.
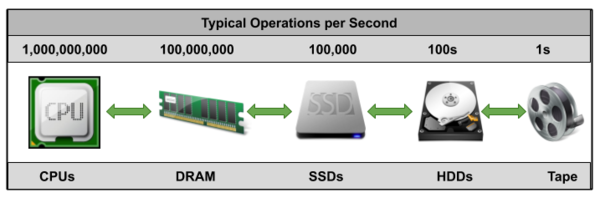 Figure 1: The data performance gap as you move further away from the CPU.
Figure 1: The data performance gap as you move further away from the CPU.
Using I/O Caching
Solid State Drives (SSDs) brought performance to the forefront of computing technologies, and their adoption is increasing not only in the data center but also in consumer-grade products. Unlike its traditional spinning hard disk drive (HDD) counterpart, SSDs comprise a collection of computer chips (non-volatile NAND memory) with no movable parts. Therefore SSDs are not kept busy seeking to new drive locations and, in turn, introducing latency. As great as this sounds, SSDs are still more expensive than HDDs. HDD prices have settled to around $0.03/GB; SSD prices vary but sit at around $0.13-$0.15/GB. At scale, that price gap makes a world of difference.
To keep costs down and still invest in the needed capacities, one logical solution is to buy a large number of HDDs and a small number of SSDs and enable the SSDs to act as a performant cache for the slower HDDs.
Common Methods of Caching
In this discussion, note that target refers to the backing store (i.e., the slower HDD). However, you should understand that the biggest pain point for a slower HDD is not accessing sectors for read and write workloads sequentially, it is random workloads and, to be more specific, random small I/O workloads that is the issue. The purpose of a cache is to alleviate a lot of the burden for the drive to seek new sector locations for 4K, 8K, or other small I/O requests. Some of the more common caching methods or modes are:
- Writeback caching. In this mode, newly written data is cached but not immediately written to the destination target.
- Write-through caching. This mode writes new data to the target while still maintaining it in cache for future reads.
- Write-around caching or a general-purpose read cache. Write-around caching avoids caching new write data and instead focuses on caching read I/O operations for future read requests.
Many userspace libraries, tools, and kernel drivers exist to enable high-speed caching. I will describe some of those more commonly used before eventually diverting attention to just dm-writecache.
dm-cache
The dm-cache component of the Linux kernel's device mapper has been around for quite some time – at least since 2006. It originally made its debut as a research project developed by Dr. Ming Zhao through his summer internship at IBM research. The dm-cache module was integrated into the Linux kernel tree as of version 3.9. It is an all-purpose caching module and is written and designed to run all of the above caching methods, with the exception of write-around caching.
bcache
Very similar to dm-cache, bcache too is a Linux kernel driver, although it differs in a few ways. For instance, the user is able to attach more than one SSD as a cache and is designed to reduce write amplification by turning random write operations into sequential writes.
Write amplification is an undesirable phenomenon wherein the amount of information physically written to the SSD is a multiple of the logical amount intended to be written. In the short term, the effects of write amplification are not felt immediately, but in the long term and as the medium begins to enforce its programmable erase (PE) cycles, making way for new write data, the life of each NAND cell is reduced.
dm-writecache
Fairly new to the Linux caching scene, dm-writecache was officially merged into the 4.18 Linux kernel. Unlike the other caching solutions mentioned already, the focus of dm-writecache is strictly writeback caching and nothing more: no read caching, no write-through caching. The thought process for not caching reads is that read data should already be in the page cache, which makes complete sense.
Other Caching Tools
Tools earning honorable mention include:
- RapidDisk. This dynamically allocatable memory disk Linux module uses RAM and can also be used as a front-end write-through and write-around caching node for slower media.
- Memcached. A cross-platform userspace library with an API for applications, Memcached also relies on RAM to boost the performance of databases and other applications.
- ReadyBoost. A Microsoft product, ReadyBoost was introduced in Windows Vista and is included in later versions of Windows. Similar to dm-cache and bcache, ReadyBoost enables SSDs to act as a cache for slower HDDs.
Working with dm-writecache
The only prerequisites for using dm-writecache are to be on a Linux distribution running a 4.18 kernel or later and to have a version of logical volume manager 2 (LVM2) installed at v2.03.x or above. I will also show you how to enable a dm-writecache volume without relying on the LVM2 framework and instead manually invoke dmsetup.
Identifying and Configuring Your Environment
Identifying the storage volumes and configuring them is a pretty straightforward process:
$ cat /proc/partitions major minor #blocks name 7 0 91264 loop0 7 1 56012 loop1 7 2 90604 loop2 259 0 244198584 nvme0n1 8 0 488386584 sda 8 1 1024 sda1 8 2 488383488 sda2 8 16 6836191232 sdb 8 32 6836191232 sdc
In my example, I will be using both /dev/sdb and /dev/nvme0n1. As you might have already guessed, /dev/sdb is my slow device, and /dev/nvme0n1 is my NVMe fast device. Because I do not necessarily want to use my entire SSD (the rest could be used as a separate standalone or cached device elsewhere), I will place both the SSD and HDD into a single LVM2 volume group. To begin, I label the physical volumes for LVM2:
$ sudo pvcreate /dev/nvme0n1 Physical volume "/dev/nvme0n1" successfully created. $ sudo pvcreate /dev/sdb Physical volume "/dev/sdb" successfully created.
Then, I verify that the volumes have been appropriately labeled:
$ sudo pvs PV VG Fmt Attr PSize PFree /dev/nvme0n1 lvm2 --- <232.89g <232.89g /dev/sdb lvm2 --- <6.37t <6.37t
Next, I add both volumes into a new volume group labeled vg-cache,
$ sudo vgcreate vg-cache /dev/nvme0n1 /dev/sdb Volume group "vg-cache" successfully created
verify that the volume group has been created,
$ sudo vgs VG #PV #LV #SN Attr VSize VFree vg-cache 2 0 0 wz--n- 6.59t 6.59t
and verify that both physical volumes are within it:
$ sudo pvs PV VG Fmt Attr PSize PFree /dev/nvme0n1 vg-cache lvm2 a-- 232.88g 232.88g /dev/sdb vg-cache lvm2 a-- <6.37t <6.37t
Say I want to use 90% of the slow disk: I will carve a logical volume labeled slow from the volume group, use that slow device,
$ sudo lvcreate -n slow -l90%FREE vg-cache /dev/sdb Logical volume "slow" created.
and verify that the logical volume has been created:
$ sudo lvs vg-cache -o+devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices slow vg-cache -wi-a----- <5.93t /dev/sdb(0)
Using the fio benchmarking utility, I run a quick test with random write I/Os to the slow logical volume and get a better understanding of how poorly it performs:
$ sudo fio --bs=4k --ioengine=libaio --iodepth=32 --size=10g --direct=1 --runtime=60 \
--filename=/dev/vg-cache/slow --rw=randwrite --numjobs=1 --name=test
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [w(1)][100.0%][r=0KiB/s,w=1401KiB/s][r=0,w=350 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=3104: Sat Oct 12 14:39:08 2019
write: IOPS=352, BW=1410KiB/s (1444kB/s)(82.8MiB/60119msec)
[ ... ]
Run status group 0 (all jobs):
WRITE: bw=1410KiB/s (1444kB/s), 1410KiB/s-1410KiB/s (1444kB/s-1444kB/s), io=82.8MiB (86.8MB), run=60119-60119msecI see an average of 1.4 kibibytes per second (KiBps) throughput. Although that number is not great, it is expected when sending a number of small random writes to an HDD. Remember, with mechanical and movable components, a large percentage of the time is spent seeking to new locations on the disk platters. If you recall, this method introduces latency and will take much longer for the disk drive to return with an acknowledgment that the write is persistent to disk.
Now, I will carve out a 10GB logical volume from the SSD and label it fast,
$ sudo lvcreate -n fast -L 10G vg-cache /dev/nvme0n1
verify that the logical volume has been created,
$ sudo lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert fast vg-cache -wi-a----- 10.00g slow vg-cache -wi-a----- 5.93t
and verify that it is created from the NVMe drive:
$ sudo lvs vg-cache -o+devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices fast vg-cache -wi-a----- 10.00g /dev/nvme0n1(0) slow vg-cache -wi-a----- 5.93t /dev/sdb(0)
Like the example above, I will run another quick fio test with the same parameters as earlier:
$ sudo fio --bs=4k --ioengine=libaio --iodepth=32 --size=10g --direct=1 --runtime=60 \
--filename=/dev/vg-cache/fast --rw=randwrite --numjobs=1 --name=test
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
fio-3.12
Starting 1 process
Jobs: 1 (f=1): [w(1)][100.0%][w=654MiB/s][w=167k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=1225: Sat Oct 12 19:20:18 2019
write: IOPS=168k, BW=655MiB/s (687MB/s)(10.0GiB/15634msec); 0 zone resets
[ ... ]
Run status group 0 (all jobs):
WRITE: bw=655MiB/s (687MB/s), 655MiB/s-655MiB/s (687MB/s-687MB/s), io=10.0GiB (10.7GB), run=15634-15634msecWow! You can see a night and day difference here of about 655MiBps throughput.
If you have not already, be sure to load the dm-writecache kernel module:
$ sudo modprobe dm-writecache
To enable the writecache volume via LVM2, you will first need to deactivate both volumes to ensure that nothing is actively writing to them. To deactivate the SSD, enter:
$ sudo lvchange -a n vg-cache/fast
To deactivate the HDD, enter:
$ sudo lvchange -a n vg-cache/slow
Now, convert both volumes into a single cache volume,
$ sudo lvconvert --type writecache --cachevol fast vg-cache/slow
activate the new volume,
$ sudo lvchange -a y vg-cache/slow
and verify that the conversion took effect:
$ sudo lvs -a vg-cache -o devices,segtype,lvattr,name,vgname,origin Devices Type Attr LV VG Origin /dev/nvme0n1(0) linear Cwi-aoC--- [fast] vg-cache slow_wcorig(0) writecache Cwi-a-C--- slow vg-cache [slow_wcorig] /dev/sdd(0) linear owi-aoC--- [slow_wcorig] vg-cache
Now it's time to run fio:
$ sudo fio --bs=4k --ioengine=libaio --iodepth=32 --size=10g --direct=1 --runtime=60 \
--filename=/dev/vg-cache/slow --rw=randwrite --numjobs=1 --name=test
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
fio-3.12
Starting 1 process
Jobs: 1 (f=1): [w(1)][100.0%][w=475MiB/s][w=122k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=1634: Mon Oct 14 22:18:59 2019
write: IOPS=118k, BW=463MiB/s (485MB/s)(10.0GiB/22123msec); 0 zone resets
[ ... ]
Run status group 0 (all jobs):
WRITE: bw=463MiB/s (485MB/s), 463MiB/s-463MiB/s (485MB/s-485MB/s), io=10.0GiB (10.7GB), run=22123-22123msecAt about 460MiBps, it's almost 330 times faster than the plain old HDD. This is awesome. Remember, the NVMe is a front-end cache to the HDD, and although all writes are hitting the NVMe, a background thread (or more than one) schedules flushes to the backing store (i.e., the HDD).
If you want to remove the volume, type:
$ sudo lvconvert --splitcache vg-cache/slow
Now you are ready to map the NVMe drive as the writeback cache for the slow spinning drive with dmsetup (in the event that you do not have a proper version of LVM2 installed). To invoke dmsetup, you first need to grab the block count of the slow device:
$ sudo blockdev --getsz /dev/vg-cache/slow 12744687616
You will plug this number into the next command and create a writecache device mapper virtual node called wc with a 4K blocksize:
$ sudo dmsetup create wc --table "0 78151680 writecache s /dev/vg-cache/slow /dev/vg-cache/fast 4096 0"
Assuming that the command returns without an error, a new (virtual) device node will be accessible from /dev/mapper/wc. This is the dm-writecache mapping. Now you need to run fio again, but this time to the newly created device:
$ sudo fio --bs=4k --ioengine=libaio --iodepth=32 --size=10g --direct=1 --runtime=60 \
--filename=/dev/mapper/wc --rw=randwrite --numjobs=1 --name=test
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
fio-3.12
Starting 1 process
Jobs: 1 (f=1): [w(1)][100.0%][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=7055: Sat Oct 12 19:09:53 2019
write: IOPS=34.8k, BW=136MiB/s (143MB/s)(9.97GiB/75084msec); 0 zone resets
[ ... ]
Run status group 0 (all jobs):
WRITE: bw=136MiB/s (143MB/s), 136MiB/s-136MiB/s (143MB/s-143MB/s), io=9.97GiB (10.7GB), run=75084-75084msecAlthough it isn't near the standalone NVMe speeds, you can see a wonderful improvement of random write operations. At 90 times the original HDD performance, you observe a throughput of 136MiBps. I am not entirely sure what parameters are not being configured for the volume during the dmsetup create to match that of the earlier LVM2 example, but this is still pretty darn good.
To remove the device mapper cache mapping, you first need to flush forcefully (and manually) all pending write data to disk:
$ sudo dmsetup message /dev/mapper/wc 0 flush
Now it is safe to enter
$ dmsetup remove /dev/mapper/wc
to remove the mapping.
Conclusion
By using the newly introduced dm-writecache device mapper Linux kernel module, you are able to achieve a noticeable improvement in random write throughput when writing to slower disk devices. Also, nothing is preventing you from using the remainder of the NVMe device in the original volume group and mapping it as a cache to other, slower devices on your system.
The Author
Petros Koutoupis is currently a senior performance software engineer at Cray for its Lustre High Performance File System division. He is also the creator and maintainer of the RapidDisk Project. Petros has worked in the data storage industry for well over a decade and has helped to pioneer the many technologies unleashed in the wild today.

