
Lead Image © Author, 123RF.com
Introducing parity declustering RAID
Silverware
Fault tolerance has been at the forefront of data protection since the dawn of computing. To this day, admins continue to struggle with efficient and reliable methods to maintain the consistency of stored data, either locally or remotely on a server (or cloud storage pool) and keep searching for the best way to recover from a failure, regardless of how disastrous that failure might be.
Some of the methods still being used today are considered ancient by today's standards. Why replace something that continues to work? One such technology is called RAID. Initially, the acronym stood for redundant array of inexpensive disks, but it was later reinvented to describe a redundant array of independent disks.
The idea of RAID was first conceived in 1987. The primary goal was to scale multiple drives into a single volume and present it to the host as a single pool of storage. Depending on how the drives were structured, you also saw an added performance or redundancy benefit. (See the box titled "RAID Recap.")
RAID Recap
RAID allows you to pool multiple drives together to represent a single volume. Depending on how the drives are organized, you can unlock certain features or advantages. For instance, depending on the RAID type, performance can dramatically improve, especially as you stripe and balance the data across multiple drives, thus removing the bottleneck of using a single disk for all write and read operations. Again, depending on the RAID type, you can grow the storage capacity.
Most of the RAID algorithms do offer some form of redundancy that can withstand a finite amount of drive failures. In such a situation, when a drive fails, the array will continue to operate in a degraded mode until you recover it by rebuilding the failed data to a spare drive.
Most traditional RAID implementations use some form of striping or mirroring (Figure 1). With a mirror, one drive is essentially a byte-by-byte image of the other(s). Striping, on the other hand, retrieves data and writes or reads it across all drives of the array in a stripe. In this method, data is written to the array in chunks, and collectively, all chunks within a stripe define the array's stripe size.
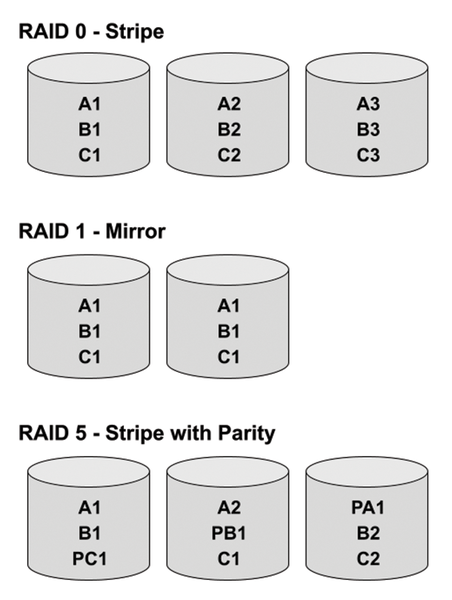 Figure 1: A general outline of RAID levels 0, 1, and 5.
Figure 1: A general outline of RAID levels 0, 1, and 5.
Common RAID types include:
RAID 0 – Disk striping. Data is written in chunks across all drives in a stripe, typically organized in a round-robin fashion. Both read and write operations access the data in the same way, and because data is constantly being transferred to or from multiple drives, bottlenecks associated with reading and writing to a single drive are alleviated, and data access performance is dramatically improved. However, RAID 0 does not offer redundancy. If a single drive or drive sector fails, the entire array fails or is immediately invalidated.
RAID 1 – Disk mirroring. In a RAID 1 array, one drive stores an exact replica of its companion drive, so if one drive fails, the second immediately steps in to resume where the first left off. Write performance tends to be half of a single drive because you are literally writing two copies of the same dataset (one to each drive). If designed properly, however, read performance can double through a mechanism called read balancing . Read requests can be split across both drives in the mirrored set so that each drive does half the work to retrieve data.
RAID 5/6 – Redundancy. Here is where things get a bit more complicated. RAID levels 5 and 6 are similar to RAID 0, except they offer a form of redundancy. Across each stripe of chunks exists a chunk dedicated to an XOR-calculated parity of all the other chunks within that same stripe. This special chunk is then balanced across all drives in the array, so that not one single drive will bear the burden of continuously writing updates to the same drive(s) every time a stripe is updated. These parity calculations make it possible to restore the original data content when a drive fails or becomes unavailable. A RAID 5 volume contains a single parity chunk per stripe. A RAID 6 volume is designed with two parity chunks per stripe, allowing it to sustain two drive failures.
Although not the focus of this article, hybrid RAID types are worth a mention. Typically hybrid types involve nesting one RAID type within another. For instance, striping mirrored sets is considered RAID 10, but if the striping includes a single parity (e.g., RAID 5), it is referred to as RAID 50.
RAID systems can be either hardware or software based. Once upon a time, processing power was limited, and it was advantageous to rely on external hardware for creating and managing RAID arrays. As time progressed, this approach became less significant. Server hardware grew more powerful, and implementing RAID solutions became much easier and less expensive through software with commodity storage drives attached to the server. However, hardware-based, vendor-specific storage arrays still exist, and they offer some additional fault tolerance and performance features that are advantageous in some settings.
RAID technology isn't perfect. As drive capacities increase and storage technologies move further away from movable components and closer to persistent memory, RAID is starting to show its age and limitations, which is why its algorithms continue to be improved.
Papers on declustering the parity of RAID 5 or 6 arrays date back to the early 1990s. The design aims to enhance the recovery performance of the array by shuffling data among all drives within the same array, including its assigned spare drives, which tend to sit idle until failure occurs.
Figure 2 showcases a very simplified logical layout of each stripe across all participating volumes. In practice, though, the logical layout is arranged randomly to distribute data chunks more evenly over the drives (and based on their logical offsets). It is done in such a way that, regardless of which drive fails, the workload to recover from the failure is distributed uniformly across the remaining drives. Figure 3 highlights a simplified example of how this is exercised with the OpenZFS project, as discussed later in this article.
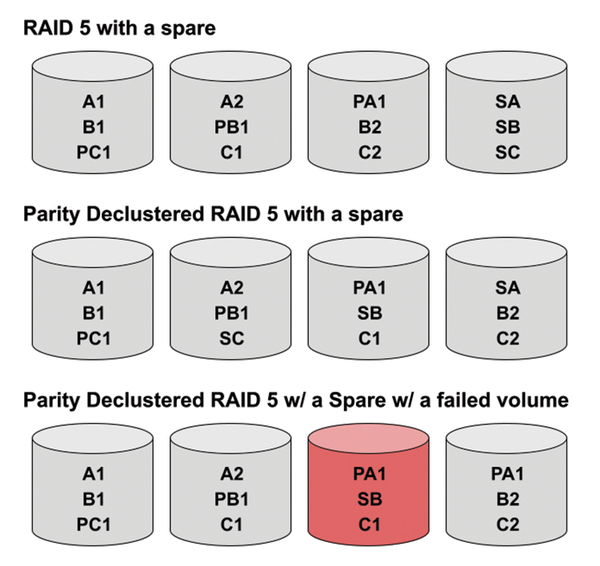 Figure 2: A simplified RAID 5 with a spare layout compared with a parity declustered layout.
Figure 2: A simplified RAID 5 with a spare layout compared with a parity declustered layout.
 Figure 3: A simplified dRAID layout compared with RAIDz. © OpenZFS project
Figure 3: A simplified dRAID layout compared with RAIDz. © OpenZFS project
Why Parity Declustering?
When a traditional redundant array fails and data needs to be rebuilt to a spare drive, two major things occur:
- Data access performance drops significantly. In parallel with user read and write requests (which involve rebuilding the original data stripe from the existing calculated parities, consuming more processing power), a background process is initiated to rebuild the original (and newly updated) data to the designated spare drive(s). This process creates a bottleneck to the spare drive.
- As a result of both activities occurring simultaneously, the recovery process will take much longer to complete. Depending on the user workload and capacity sizes, we are talking about days, weeks, even months. In the interim, however, you have the risk of a secondary (or tertiary) drive failing; depending on the RAID type, it can put your array into an extremely vulnerable state – if not cripple the entire array and render your data unrecoverable.
By leveraging parity declustering, all drives within the array, including the spares, participate in the data layout with specific regions of a stripe dedicated as the spare chunks. When the time comes to regenerate and recover lost data because of a drive failure, all drives participate in the recovery process and, in turn, do not bottleneck a single drive (i.e., the spare). This method means a reduced rebuild time, and when the existing array is under a heavier user workload, this matters.
OpenZFS dRAID
How does one take advantage of this approach to data management? Fortunately, and fairly recently, in a joint vendor and community effort, the OpenZFS http://1]project recently introduced parity declustering. The implementation, called distributed RAID (dRAID), was released in OpenZFS version 2.1 http://2.
As an example, to configure a single-parity dRAID volume with a single spare volume on five drives, you would use the zpool command-line utility:
# zpool create -f myvol2 draid:3d:1s:5c /dev/sd[b-f]
In this example, if you want dual or triple parity, you would instead substitute draid with draid2 or draid3. The next colon-delimited field defines the number of data drives (in this case, three), then the number of spare drives, and finally the total number of children. If executed without error, zpool status would output something like Listing 1. For reference purposes, with a traditional single-parity RAIDz pool and a single spare, the output would look something like Listing 2.
Listing 1
dRAID zpool status
¤¤nonumber
# sudo zpool status
pool: myvol2
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
myvol2 ONLINE 0 0 0
draid1:3d:5c:1s-0 ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
sde ONLINE 0 0 0
sdf ONLINE 0 0 0
spares
draid1-0-0 AVAIL
errors: No known data errors
Listing 2
RAIDz zpool status
¤¤nonumber
# zpool status
pool: myvol1
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
myvol1 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
sde ONLINE 0 0 0
spares
sdf AVAIL
errors: No known data errors
Notice that in the dRAID example, all drives, including the spare, are active in the pool, whereas in the RAIDz example, a single spare drive remains idle until a failure occurs.
To exercise this feature, you will need to "fail" a drive; the quickest way to do so is to take it offline by the storage subsystem in sysfs (in Linux):
# echo offline >/sys/block/sdf/device/state
When the drive failure is detected on the next I/O operation to the pool, the distributed spare space will step in to resume where the failed drive left off (Listing 3).
Listing 3
Spare Drive Stepping In
¤¤nonumber
# zpool status
pool: myvol2
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J
scan: scrub in progress since Mon Oct 24 17:11:22 2022
80.7M scanned at 80.7M/s, 133M issued at 133M/s, 81.6M total
0B repaired, 163.06% done, no estimated completion time
scan: resilvered (draid1:3d:5c:1s-0) 20.2M in 00:00:00 with 0 errors on Mon Oct 24 17:11:22 2022
config:
NAME STATE READ WRITE CKSUM
myvol2 DEGRADED 0 0 0
draid1:3d:5c:1s-0 DEGRADED 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
sde ONLINE 0 0 0
spare-4 DEGRADED 0 0 0
sdf UNAVAIL 3 397 0
draid1-0-0 ONLINE 0 0 0
spares
draid1-0-0 INUSE currently in use
errors: No known data errors
The next step is to take the failed drive from the ZFS pool offline to simulate a drive replacement:
# zpool offline myvol2 sdf # echo running >/sys/block/sdf/device/state # zpool online myvol2 sdf
A resilver (resyncing, or rebuilding, a degraded array) is initiated across all drives within the pool (Listing 4).
Listing 4
Resilvering
¤¤nonumber
# zpool status
pool: myvol2
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Mon Oct 24 17:13:44 2022
15.0G scanned at 3.00G/s, 5.74G issued at 1.15G/s, 15.0G total
709M resilvered, 38.29% done, 00:00:08 to go
config:
NAME STATE READ WRITE CKSUM
myvol2 ONLINE 0 0 0
draid1:3d:5c:1s-0 ONLINE 0 0 0
sdb ONLINE 0 0 0 (resilvering)
sdc ONLINE 0 0 0 (resilvering)
sdd ONLINE 0 0 0 (resilvering)
sde ONLINE 0 0 0 (resilvering)
spare-4 ONLINE 0 0 0
sdf ONLINE 3 397 0 (resilvering)
draid1-0-0 ONLINE 0 0 0 (resilvering)
spares
draid1-0-0 INUSE currently in use
errors: No known data errors
Conclusion
The OpenZFS project is the first freely distributed open source storage management solution to offer a parity declustered RAID feature. As stated earlier, the biggest advantage to using dRAID is that resilvering times are greatly reduced over the traditional RAIDz, and restoring the pool back to full redundancy can be accomplished in a fraction of the time. As drive capacities continue to increase, this feature alone will continue to show its value.
Infos
- OpenZFS Project page: https://www.openzfs.org
- OpenZFS dRAID documentation: https://openzfs.github.io/openzfs-docs/Basic%20Concepts/dRAID%20Howto.html
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Linux Software RAID

Manage storage by building software RAID with the Linux mdadm command.
-
Software RAID in Windows, macOS, and Linux
 If RAID hardware is missing on your server, Windows, Linux, and macOS offer various options for building software RAID.
If RAID hardware is missing on your server, Windows, Linux, and macOS offer various options for building software RAID. - RAID Inc. Announces New RAID Solution
-
Tuning SSD RAID for optimal performance
 Hardware RAID controllers are optimized for the I/O characteristics of hard disks; however, the different characteristics of SSDs require optimized RAID controllers and RAID settings.
Hardware RAID controllers are optimized for the I/O characteristics of hard disks; however, the different characteristics of SSDs require optimized RAID controllers and RAID settings. -
Creating Virtual SSDs

An economical and high-performing hybrid NVMe SSD is exported to host servers that use it as a locally attached NVMe device.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
