
Photo by Quino Al on Unsplash
Analyzing tricky database problems
Set Theory
Troubleshooting complex cloud infrastructures can quickly look like finding the proverbial needle in a haystack. Nevertheless, the effort can be worthwhile, as shown by a practical example at the Swiss foundation Switch. The foundation has been organizing the networking of all Swiss university IT resources for more than 30 years [1]. In addition to Swiss universities, the Switch community also includes other institutions from the education and research sectors, as well as private organizations (e.g., financial institutions or industry-related research institutions).
Because of its high degree of networking, Switch depends on a powerful cloud infrastructure. The foundation provides tens of thousands of users with the Switch Drive file-sharing service, which is based on ownCloud, is hosted 100 percent on Swiss servers, and is used mainly for synchronizing and sharing documents (Figure 1).
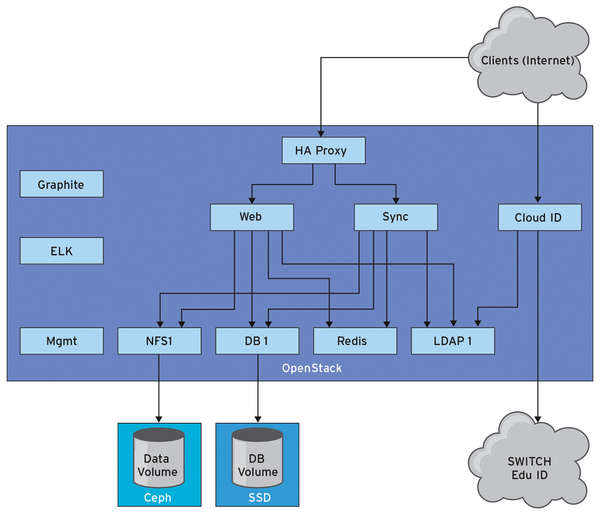 Figure 1: Overview of the Switch server infrastructure.
Figure 1: Overview of the Switch server infrastructure.
Switch Drive is essentially an ownCloud offering under the Switch brand that manages 30,000 users and about 105 million files. The oc_filecache table contains about 100 million lines. To manage this high number, six MariaDB servers [2] are used in Galera Cluster
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
MariaDB MaxScale: A smart proxy for MySQL
 MaxScale by MariaDB is a smart proxy server for MySQL that speaks the same protocol as the database server. The manufacturer claims solid high availability and horizontal scalability.
MaxScale by MariaDB is a smart proxy server for MySQL that speaks the same protocol as the database server. The manufacturer claims solid high availability and horizontal scalability. -
Optimizing SQL with Execution Plans
Understanding database execution plans is the key to assessing effectively the optimum potential of an SQL query or estimating your future resource requirements.
-
Maatkit tools for database administrators
The Maatkit tool suite helps administrators with performance tuning and other tasks for MySQL and other databases.
-
Manage status messages in CouchDB with MapReduce
 CouchDB offers numerous interesting features for acquisition and filtering of status messages that make it a fast and convenient data storage solution.
CouchDB offers numerous interesting features for acquisition and filtering of status messages that make it a fast and convenient data storage solution. -
Five graphical database front ends
 Skillfully formulated SQL statements are not everyone's favorite pastime. But graphical front ends can help manage data, so even newcomers will benefit from complex data collections.
Skillfully formulated SQL statements are not everyone's favorite pastime. But graphical front ends can help manage data, so even newcomers will benefit from complex data collections.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
